Why Netflix Knows You Better Than Your Best Friend: Cracking the Cold Start Problem
Why Netflix Knows You Better Than Your Best Friend: Cracking the Cold Start Problem
You just finished watching a tear-jerking documentary about ocean conservation, and Netflix immediately recommends a slasher horror film. Or you buy a single printer on Amazon and for the next six months every visit drowns you in cartridge ads. We have all been there — that awkward moment when a platform that claims to "know you" clearly does not. But here is the more interesting question: how does it get things so right the rest of the time? And why is getting it right at the very beginning so incredibly difficult?

The Engine Behind the Magic: What We Learned in Class
Modern recommendation systems rely heavily on a technique called Collaborative Filtering (CF) — the idea that if two people have agreed on many things in the past, they will likely agree on new things in the future. There are two main flavours:
- User-Based CF — The system finds users who are similar to you (your "taste twins") and recommends what they liked. If you and another user both rated three of the same indie films highly, the algorithm assumes you might also enjoy the fourth film they loved.
- Item-Based CF — Instead of comparing people, the system compares items. If "Interstellar" and "Arrival" are consistently rated similarly by thousands of users, the system learns they are related and recommends one to anyone who enjoyed the other.
Both approaches depend on a User-Item Rating Matrix — a giant spreadsheet where every row is a user, every column is a movie or product or song, and each cell holds a rating or interaction signal. The algorithm scans this matrix to detect patterns of similarity.
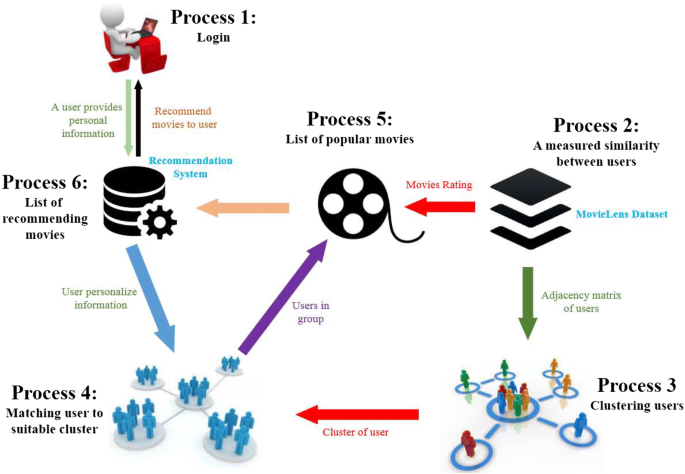
A high-level view of the recommendation pipeline — from raw interaction data to personalized suggestions
But there is a big catch. In the real world this matrix is almost entirely empty. A platform like Netflix has millions of users and hundreds of thousands of titles; the average person has rated only a tiny fraction of them. This massive emptiness is called Sparsity, and it makes finding reliable similarity patterns extremely difficult. The problem gets worse with a brand-new user who has rated nothing at all — the system has zero data to work with. This is the infamous Cold Start Problem: how do you recommend something meaningful to someone you know absolutely nothing about?
The Cold Start problem — a new user or new item with no history leaves the algorithm with nothing to work from
The Research Spotlight: A Smarter First Handshake
A compelling answer to this challenge comes from a 2019 paper titled "A Hybrid Collaborative Filtering Model with Deep Neural Networks for Solving Cold Start Problem" by Sungwoon Choi and Heonchang Yu, published in the Journal of Intelligent Information Systems. The paper targets the cold start scenario head-on — specifically, what happens when a completely new user joins a platform and the system must still provide useful recommendations from day one.
The researchers' insight is elegant: instead of waiting for a new user to build up a rating history, why not use information the platform already has? Their proposed system combines two sources of knowledge. First, it draws on side information — things like user profile data (age range, location, stated preferences) and item metadata (genre, cast, keywords). Second, it feeds all of this into a deep neural network that learns complex, non-obvious patterns far beyond what a simple matrix comparison can detect. The result is a Hybrid System: part traditional collaborative filtering, part deep learning, working together so that even a day-one user gets recommendations that feel surprisingly personal — not just a generic "top 10 trending" list.
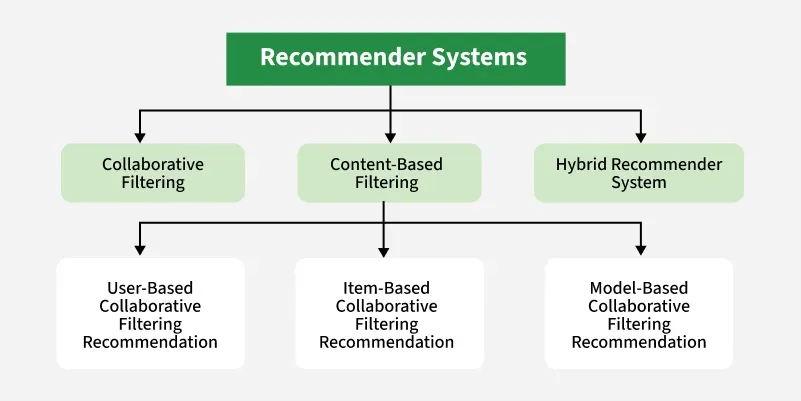
Hybrid systems combine Collaborative Filtering and Content-Based signals — the approach at the heart of this research
The results were encouraging. In experiments on the MovieLens and Amazon product datasets — two popular benchmarks in this field — the hybrid model outperformed standard collaborative filtering baselines, particularly in cold start scenarios. The accuracy improvement was most pronounced when users had fewer than five prior interactions, exactly the situation where traditional CF falls flat. In plain English: the system got noticeably better at guessing what a brand-new person would enjoy, simply by being smarter about the background clues already available.

Matrix Factorization — the mathematical backbone that helps the model uncover hidden latent factors connecting users and items
How the Pipeline Actually Works
To make this even clearer, here is the simplified pipeline the hybrid model follows from raw data to final recommendation:
New User Arrives (Zero Rating History)
↓
Collect Side Information (Profile, Demographics, Item Metadata)
↓
Feed Into Deep Neural Network
↓
Neural Net Learns Latent User & Item Representations
↓
Combine With Collaborative Filtering Signals (if any data exists)
↓
Rank Candidate Items
↓
Serve Personalised Recommendations — Even on Day One
What Does This Mean for You?
Next time Spotify nails a song recommendation on your very first day, or Netflix somehow suggests the perfect show before you have watched a single episode — there is a good chance a hybrid model like the one described in this paper is quietly working in the background. The cold start problem is not fully "solved" — it remains one of the most active research areas in machine learning — but papers like this one are steadily closing the gap between a system that guesses randomly and one that genuinely understands your taste from the very first click.
The broader lesson is also worth noting: the best recommendation systems today are not purely mathematical engines — they are thoughtful combinations of behavioral data, background knowledge, and deep learning, all working together to make you feel seen the moment you walk through the digital door.
Question for the comments: Do you think platforms like Netflix or Spotify should be more transparent about why they are recommending something to a new user — for example, showing "we suggested this based on your age group and location" rather than presenting it as if they already know you? Would that honesty make the experience better or worse?


This was a very informative read. I liked how the blog highlighted why the cold start problem is such a major issue in recommender systems, especially when a new user or item has little or no historical interaction data.
ReplyDeleteDo you think hybrid recommender systems (combining collaborative and content-based methods) are currently the most effective approach to solving this problem in real-world systems?
Really insightful explanation of the cold start problem! I especially liked how the article clarified the difference between new user and new item scenarios. It’s interesting how recommendation systems struggle when there is little interaction data available, since most algorithms rely heavily on historical behavior.
ReplyDeleteI really liked how the article simplified the idea of Netflix’s recommendation system. The point about how the platform learns from viewing behavior—like what we watch, when we watch, and how long we watch—was especially interesting. It’s amazing that such systems can personalize suggestions so accurately using machine learning and user interaction data
ReplyDeleteVery informative article! It helped me understand why new users initially receive generic recommendations.
ReplyDeleteGreat article! The discussion about how recommender systems initially lack enough data to make accurate suggestions was very clear. The cold start challenge is fascinating because it directly affects user engagement during the first interactions with a platform.
ReplyDelete