User-Based Collaborative Filtering: How Recommendation Systems Find Similar Users
User-Based Collaborative Filtering: How Recommendation Systems Find Similar Users
If someone with the same taste as you loved a movie you haven't watched yet, chances are you might love it too. This idea forms the foundation of User-Based Collaborative Filtering.
Introduction
Recommendation systems are used by platforms such as Netflix, Amazon, and Spotify to personalize user experiences. These systems analyze user behavior and suggest items that a user is likely to enjoy.
One of the earliest and most intuitive techniques used in recommendation systems is User-Based Collaborative Filtering. Instead of analyzing product features, this approach analyzes similarities between users.
The Core Idea
User-based collaborative filtering assumes that users who had similar preferences in the past will continue to have similar preferences in the future.
The recommendation process generally follows three main steps:
- Identify users with similar interests
- Find items those users liked
- Recommend those items to the target user
User Similarity Concept
The system compares users by analyzing their interaction history such as ratings, purchases, watch time, or clicks. Users with highly similar interaction patterns are considered nearest neighbors.
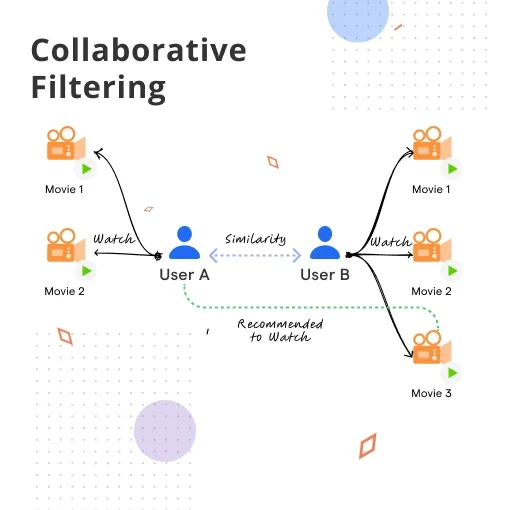
Example visualization of collaborative filtering where similar users influence recommendations.
User–Item Interaction Matrix
User interactions are typically represented using a User–Item Matrix. Rows represent users and columns represent items.
| User | Movie A | Movie B | Movie C | Movie D |
| Alice | 5 | 4 | — | 5 |
| Bob | 5 | 4 | 5 | 4 |
| Carol | 2 | 1 | 3 | 2 |
Since Alice and Bob have very similar ratings, Bob becomes Alice's nearest neighbor. If Bob liked Movie C and Alice hasn't watched it yet, the system recommends Movie C to Alice.
Similarity Measures
To determine how similar users are, recommendation systems apply mathematical similarity metrics.
- Cosine Similarity
- Pearson Correlation
- Jaccard Similarity
Cosine Similarity
Cosine similarity measures the angle between two user rating vectors. If the angle between the vectors is small, the similarity score is high.

Cosine similarity measures the angle between two vectors to determine similarity.
Pearson Correlation
Pearson correlation adjusts ratings relative to each user's average rating. This helps when users have different rating scales.
Recommendation Algorithm (Simplified)
- Construct the user-item interaction matrix
- Compute similarity between the target user and other users
- Select the top-K most similar users
- Predict ratings using weighted averages
- Recommend items with the highest predicted ratings
Python Example
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
alice = np.array([5,4,0,5])
bob = np.array([5,4,5,4])
similarity = cosine_similarity([alice],[bob])
print("Similarity Score:", similarity)
Advantages
- Simple and intuitive recommendation approach
- No need for item metadata
- Works across different domains
Limitations
- Cold start problem for new users
- Data sparsity in large datasets
- High computational cost for large platforms
Conclusion
User-Based Collaborative Filtering remains one of the most foundational techniques in recommendation systems. By leveraging collective user behavior, platforms can provide highly personalized suggestions without requiring detailed knowledge about item features.
In the next article, we will explore Item-Based Collaborative Filtering, which focuses on relationships between items rather than users.



Comments
Post a Comment